Over the past months, we have been preparing to move subsets of content from the classic CDS (cds.cern.ch) to the new CERN Repository (repository.cern). Today, we’re happy to share a big milestone in that journey:
The full CERN IT Department collection — more than 60,000 records — has now been migrated to the new repository.
The IT Department collection contains a wide range of material: technical reports, internal documentation, presentations, project notes, and other outputs produced by CERN’s IT community over many years.
All of these records have now been transferred from cds.cern.ch to repository.cern, preserving:
Metadata and descriptions
Attached files
Links and identifiers
Community structure and visibility settings
In short: the content is the same, but the platform is new.
Why this matters
This migration is more than just a change of URL.
The new CERN Repository is designed to support modern workflows: better search, cleaner record pages, structured communities, and integrated review toold. Moving a large and active collection like IT’s is an important step in validating that the platform works at scale — not just for small pilot communities, but for real production collections with long histories.
It also means IT Department records are now ready to benefit from new features as they are released — including in-place review discussions, improved curation tools, and future integrations.
What does this mean for users?
If you used the IT collection on cds.cern.ch before:
Your records are still available
Links have been preserved or redirected where possible
You can browse the collection in the new interface
Future submissions and updates will happen in repository.cern
The old CDS instance remains available for reference during the transition period, but new work of migrated IT department is now expected to take place on the new repository.
Are you from the IT department and planning to go for a conference? Will you create an article/preprint/poster/presentation or other document? You worked on a report and looking for a place to preserve it for the future? The new CDS platform is the place to go!
Moving 60,000 records is not a small task. This required:
Data extraction from the legacy CDS
Metadata mapping to the new repository model
File migration and integrity checks
Community structure recreation
Extensive validation by the CDS team
What’s next?
The IT collection migration is part of the broader transition of CERN communities to the new repository. More departmental and collaboration collections will follow in the coming months.
As always, we’ll keep sharing progress here on the CDS blog — and we welcome feedback as people start using the new platform for day-to-day work.
If you spot anything odd in the migrated records or have questions about the new collection, reach out through the CDS support channels. We’re happy to help.
If you’ve ever reviewed a submission in CDS and ended up juggling email threads, chat messages, and half-remembered notes — this update is for you.
We’ve just rolled out improved commenting features in repository.cern (new CDS platform). That means discussions about submissions will be easier to navigate and use!
We also added 3D images previewer and few copy buttons to facilitate record links distribution – to share with your colleagues or your users.
You can read the full comments feature documentation here:
Disclaimer: the full documentation is still under construction 🏗️ and will be gradually updated
But below is the short version of what’s new — and why it should make your life easier.
What’s new?
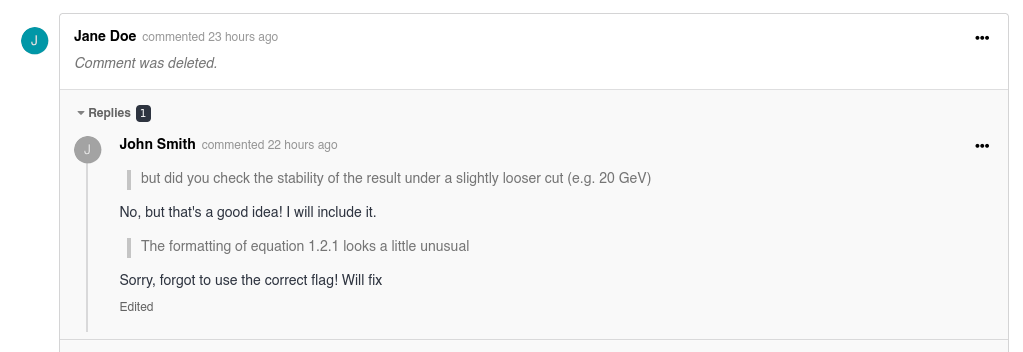
Improved submission review comments
When a record is submitted for review, reviewers and submitters can now:
Reply to specific comments in threaded discussions
Quote another comment when responding
Share a direct link to a comment
Use simple formatting and LaTeX for equations
Temporarily keep draft comments auto-saved in the browser
Lock discussions when a review is finished
What does it mean in practice? No more copy-pasting comments back and forth. No more losing long responses because a browser tab was accidentally closed.
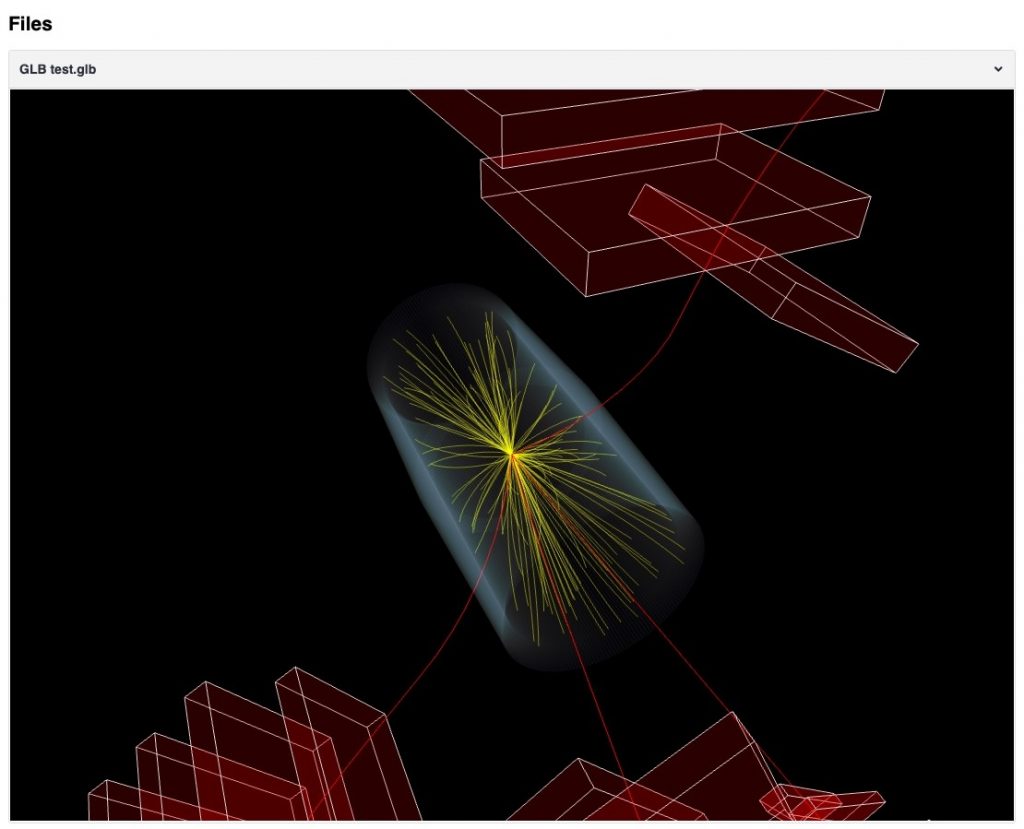
File previewer
From now on GLB files can be viewed directly on the record page:
3D event previewer
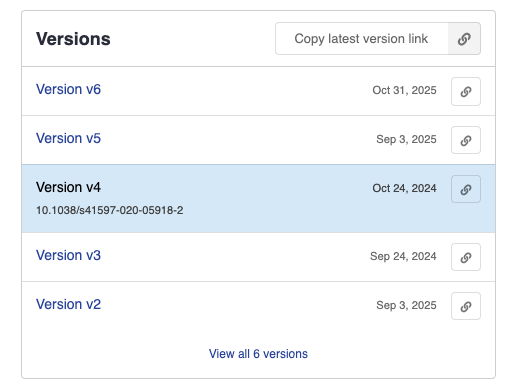
Version aware sharing
Would you like to share a link pointing always to the latest version of the record, but you don’t need a DOI? Or instead, do you really need a link to one of the previous versions? Use these new link 🔗 buttons:
Why we built this
CDS reviews are often collaborative: collaboration librarians, editors, conveners, authors — everyone has a say. Until now, most of that discussion happened outside the repository. That made it hard to track decisions and context over time.
With in-place commenting:
Feedback stays attached to the submission
Everyone sees the same discussion
It’s easier to follow what has been addressed and what hasn’t
Future curators can understand why a decision was made
Curators can lock the discussion once the review is complete, so the conversation stays as a record of the process.
This is a part of the process
We see this as the first step toward smoother community workflows in the CDS platform. As always, we’ll keep improving based on how people actually use the system.
If you run into issues or have ideas for improvements, let us know through the usual CDS support channels.
Thanks to everyone who tested early versions and provided feedback — it helped shape this release.
Over the past months, CDS has been experiencing a very high volume of automated traffic originating from all over the world.
These requests, coming from bots, AI crawlers and various scripts, have intermittently impacted the stability and performance of the platform. To put it bluntly, CDS has been unreachable far too often lately, and we are not proud of it. We constantly strive to provide a high-quality and reliable service.
We continuously block aggressive crawlers and, unfortunately, this sometimes affects legitimate users as well.
Because our efforts are concentrated on the migration to the new platform, we aim to minimise the work required for heavy and complex infrastructure changes to CDS.
To ensure CDS remains reliable and responsive, we will however implement a set of infrastructure changes in the coming weeks. Most of these updates will be fully transparent to users.
Mandatory HTTPS
From now on, all HTTP traffic will be automatically redirected to HTTPS. This improves security and helps us better manage incoming traffic.
In principle, this change should be completely transparent. If you experience access issues, please make sure any bookmarks, scripts or integrations use https:// URLs only.
Controlled searches
We have deployed traffic-management measures for the CDS search functionality. Under specific conditions, certain searches may be blocked. Users accessing CDS from the CERN network will not be affected by these limits.
Other improvements to better handle traffic
We will deploy internal infrastructure updates that allow us to better control, filter and limit harmful traffic patterns. These adjustments are not expected to affect normal usage.
If you encounter any problems following these changes, please contact us. We are here to help.
We’re excited to announce a set of powerful new features on CDS Videos! These updates make it easier than ever to upload, navigate, explore and share video content. Let’s dive in.
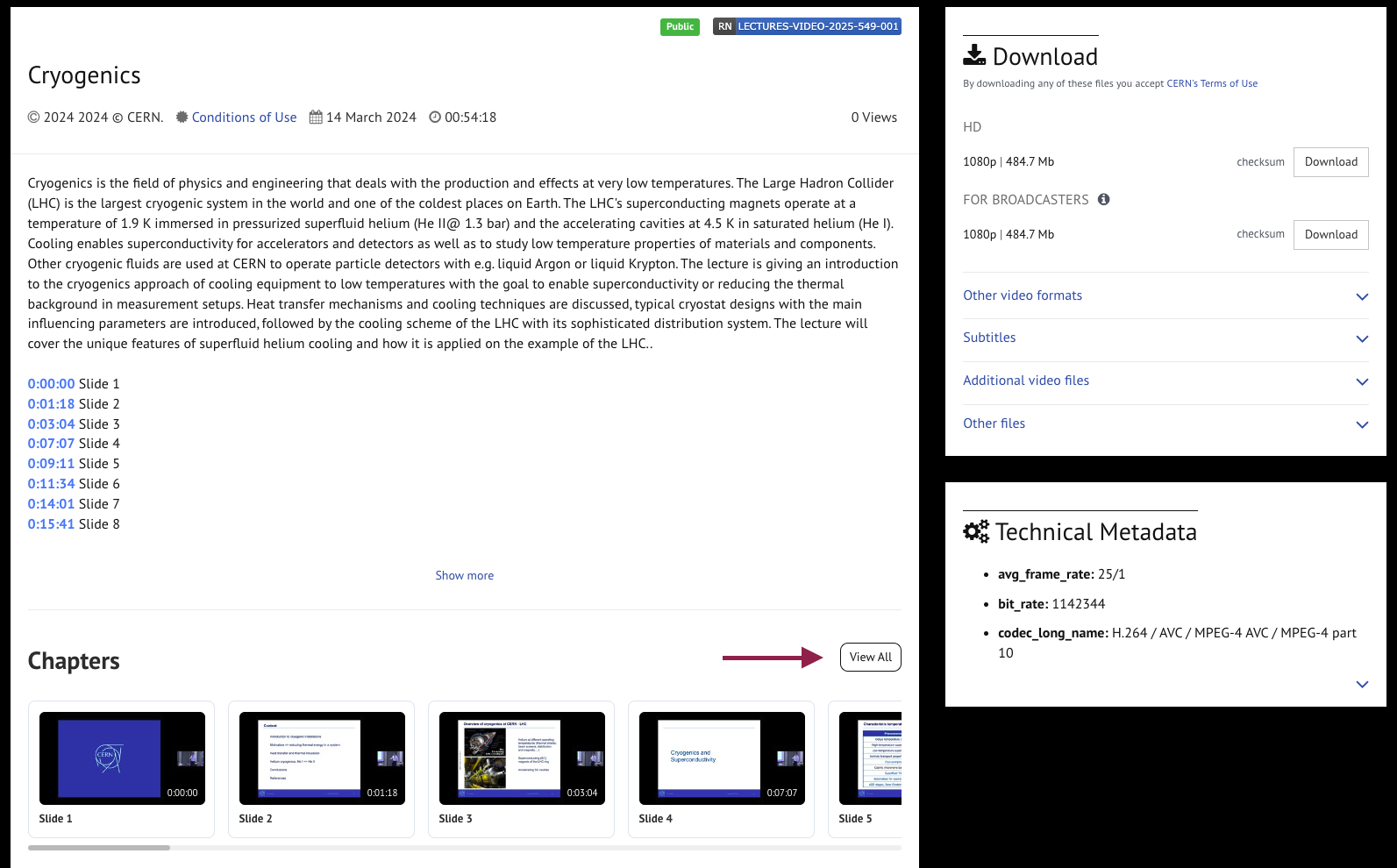
Video Chapters: Add and browse
Now CDS Videos supports video chapters. Chapters make long videos easier to explore, and let you create more structured videos. With chapters, you can divide your video into sections and viewers can easily follow the content and jump directly to any chapter.
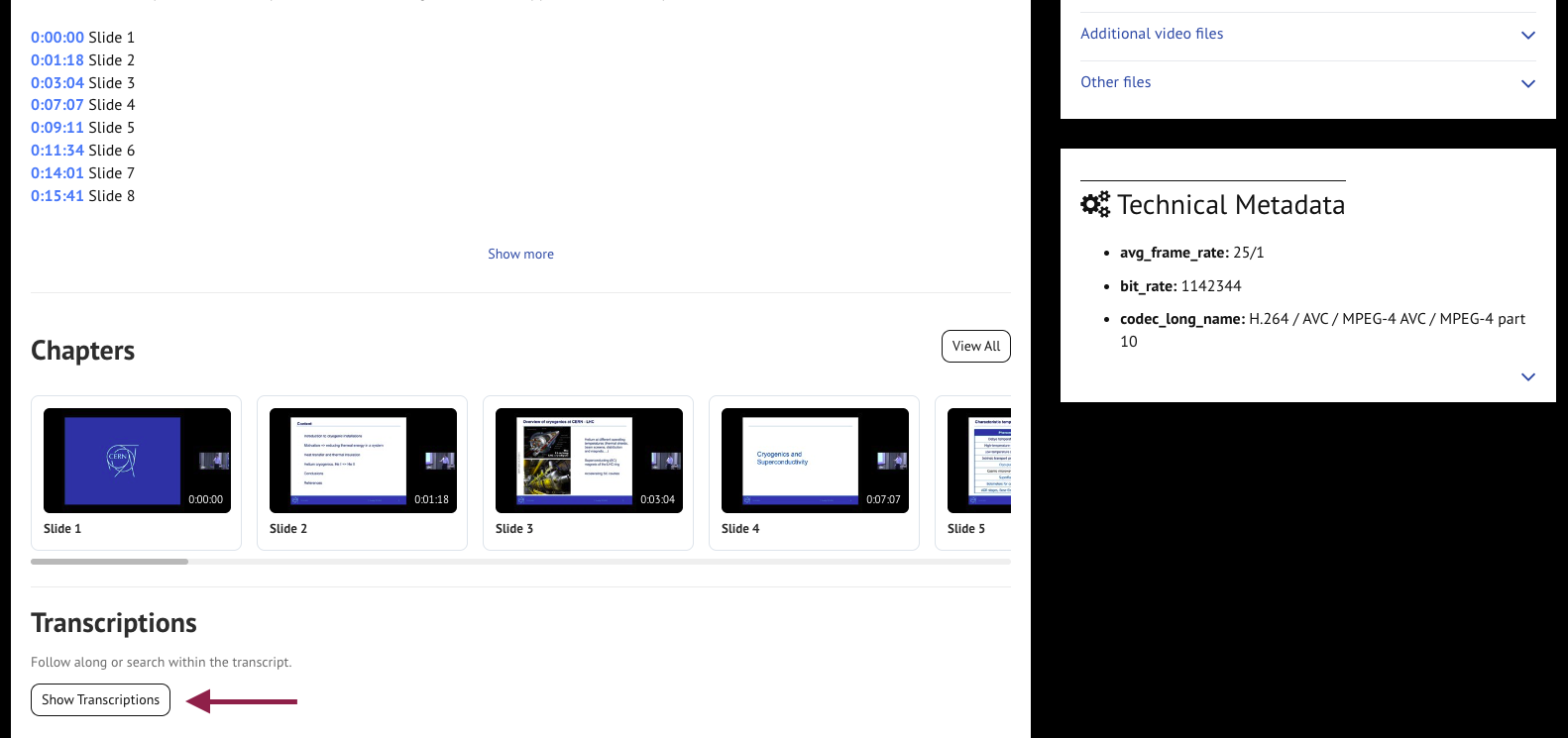
If a video video has chapters, you’ll see clickable timestamps in the description and a “Chapters” section.
Clicking “View All” will open a side panel with all chapters listed.
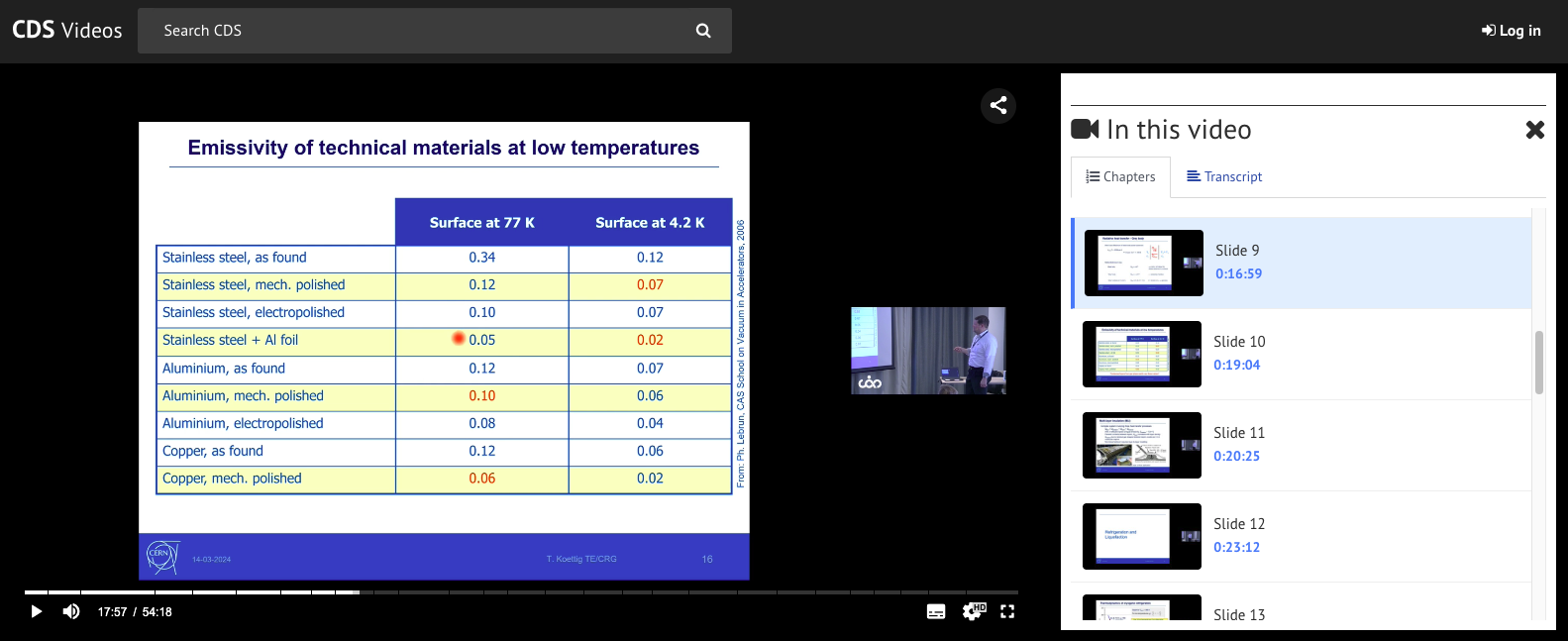
Published video page: Chapters
You can:
Browse chapters and jump instantly.
See chapters directly in the video player.
Video page: side panel with Chapters
How to add chapters to your video
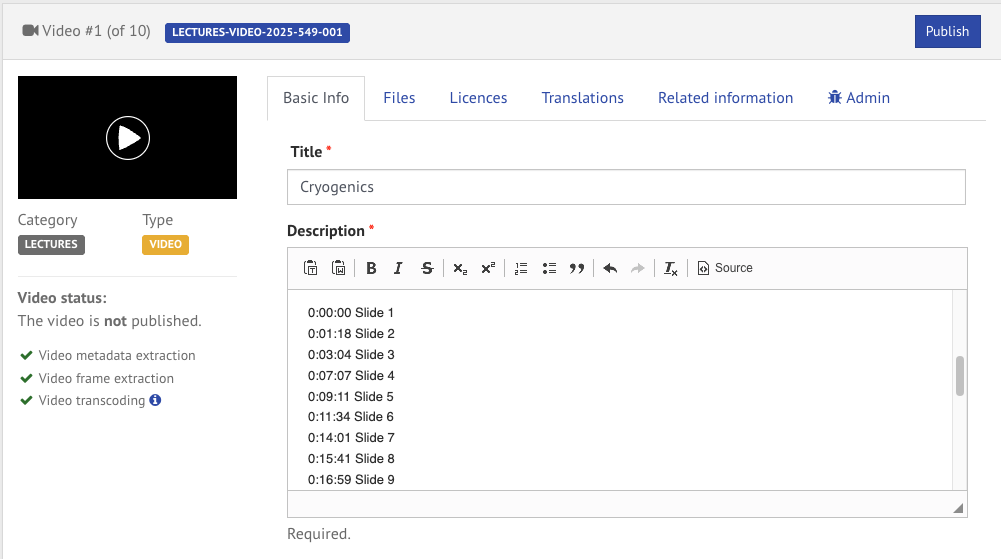
If you want to add chapters to your video, all you have to do is to just type your timestamps and titles in the description, using one of the following format:
hh:mm:ss Title
mm:ss Title
The system will automatically detect these lines and create chapters for you.
Note: Make sure that the first timestamp starts with 00:00.
Video edit page: Add chapter timestamps to description
Until now, you could only upload non-video files (e.g. PDFs, slides) as additional files.
With the new update:
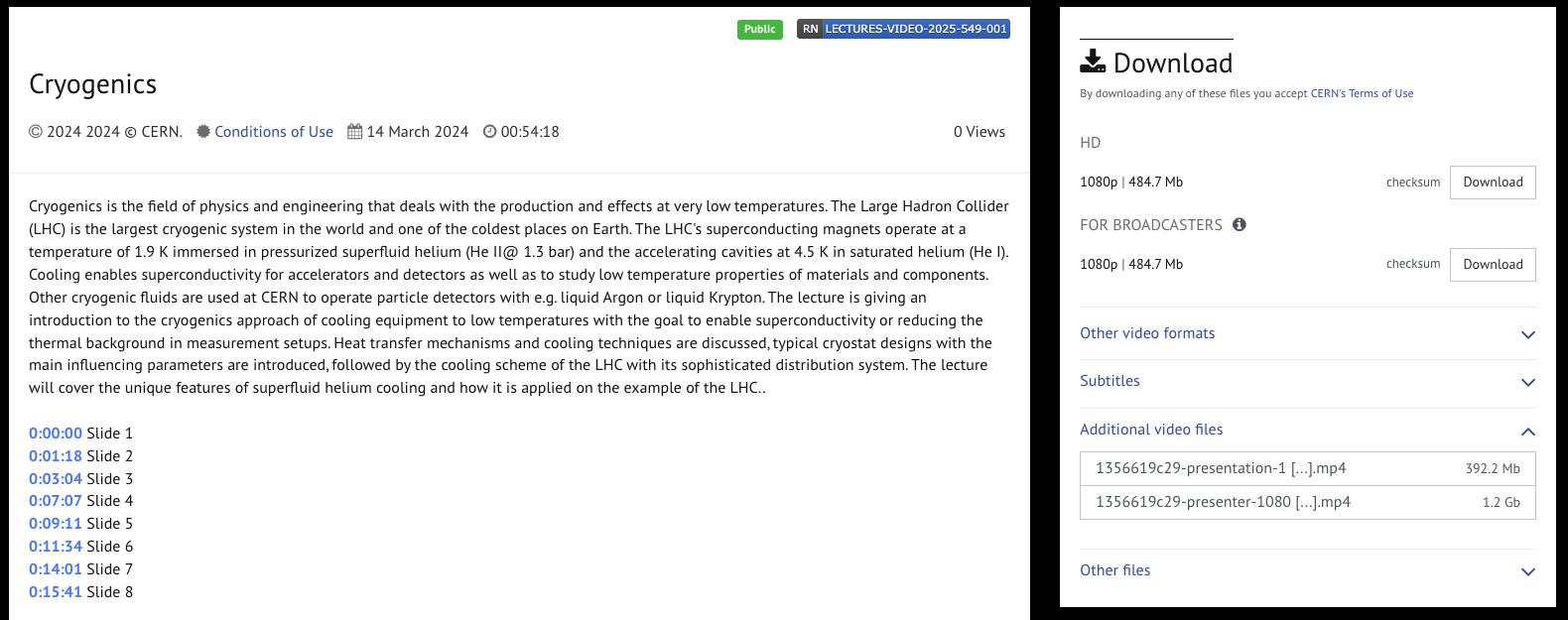
You can upload video files as additional files.
Replacing the main video file is now handled separately, with a dedicated section.
This makes it easy to provide additional supportive video content in alongside the main video.
Video edit page: separate upload for main and additional files
Video page: download section for additional video files
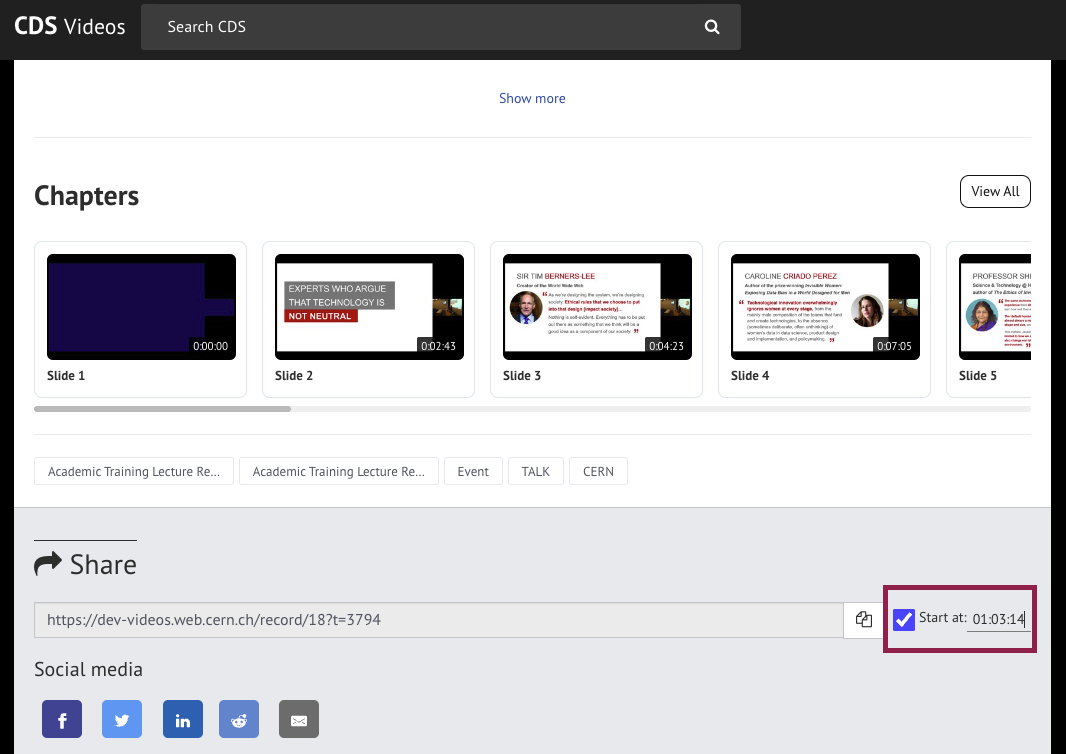
Share videos from a specific time
Now you can share a link to your video starting at a specific time.
In the Share section of the published video, you can set the starting time (e.g. 05:32 or 01:12:45).
Copy and share the link, and the users will jump straight to that time when they navigate to your video!
Video page: Share with a specific time
Perfect for highlighting a key moment in a talk or lecture.
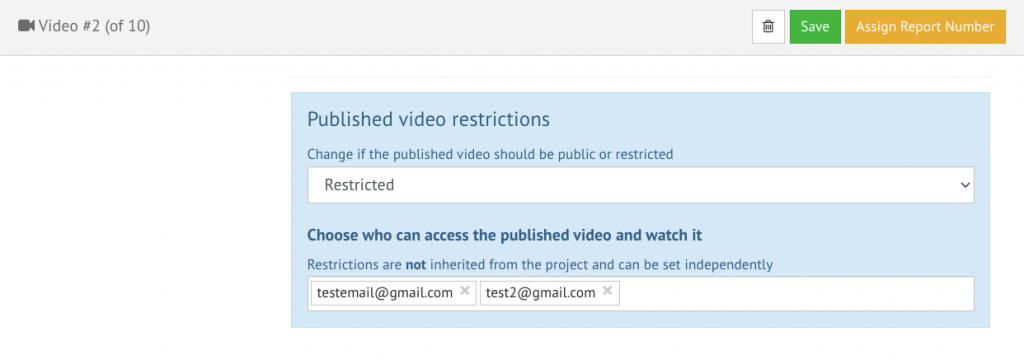
Login is available now for users without CERN account
Previously, only users with CERN accounts could log in to the platform and view restricted videos.
Now, users without a CERN account can also log in and watch restricted videos if they have permission. However they can’t upload or edit.
You can give access to view your restricted published videos to any user.
Video edit page: Restrict who can watch your video
This makes sharing restricted videos with collaborators outside CERN much easier.
Looking ahead
With these improvements, CDS Videos becomes more user-friendly and collaborative, while offering a modern experience familiar from mainstream video platforms.
Whether you’re uploading content, guiding viewers with chapters, enabling subtitles, or sharing key moments, these features help your audience connect and collaborate more easily.
Stay tuned for more updates as we continue to expand and improve CDS Videos.
We’re thrilled to announce the successful migration of all theses from our previous platform (https://cds.cern.ch) to our new CERN Repository (https://repository.cern)! The dedicated teams from CDS and the Scientific Information Service have worked tirelessly over the past months to achieve this significant milestone.
Where are theses now?
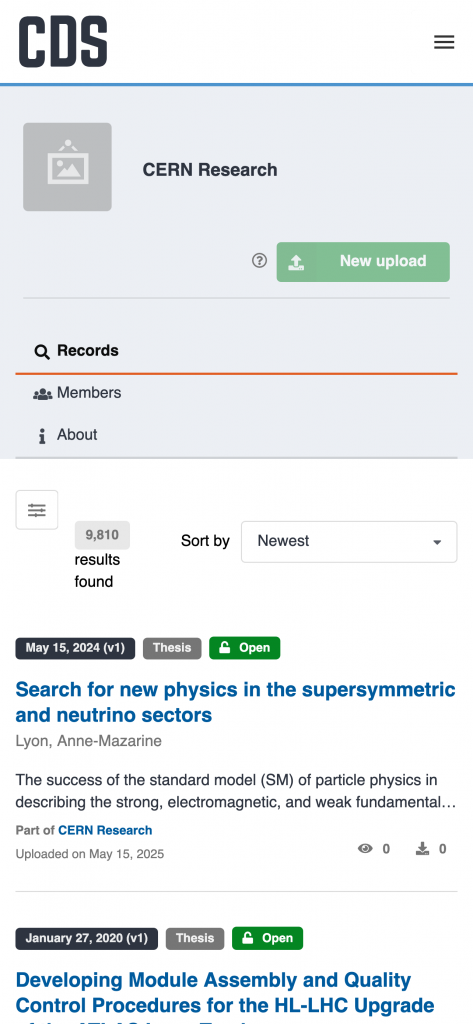
Finding CERN theses on our new platform is now easier than ever! All our thesis collections have been successfully migrated. You can find them simply by performing a search (with or without keywords) and then selecting the Thesis resource type from the left sidebar filter. Try searching for all Theses now!
Migrated theses
In the coming weeks, we will be adding even more filters to help you narrow down your search results by department, experiment, or accelerator. In the meantime, you can achieve the same by using specific search keywords like department:EP or experiment:FASER.
How do I submit a thesis?
Submitting your thesis to the new repository is a straightforward process! The Scientific Information Service has prepared a clear and concise documentation page to guide you through the steps. Simply navigate to the brand-new CERN Research community in the CERN Repository and click on the “New upload” button.
New upload button in the CERN Research community
All submitted theses will undergo careful review and curation by the CERN Scientific Information Service team.
Existing Links
We understand the importance of persistent links. Rest assured that all existing links to theses on the previous platform (CDS) will automatically redirect to the corresponding records on the new CERN Repository. You won’t need to update your bookmarks or shared links.
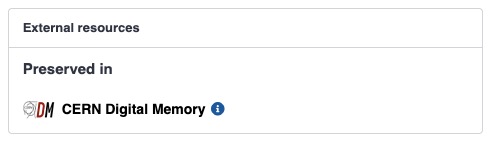
Data Preservation
The long-term preservation of CERN’s research output is a top priority. The new CERN Repository is integrated with the CERN Digital Memory service, to ensure that your valuable work remains accessible for future generations of researchers. Your content will be securely stored and managed for the long term.
CERN Digital Memory service integration
Mobile Accessibility
We know that many of you access information on the go. The CERN Repository is built with a responsive design, meaning the platform adapts seamlessly to different screen sizes, including smartphones and tablets. You’ll be able to easily search, browse, and access theses on your mobile devices without any issues.
Next steps
Following this initial phase focused on fixes and improvements to the thesis submission workflow, we will continue our migration journey, concentrating on collections that do not involve complex features or workflows. Stay tuned for further updates!
Help and contacts
We’re here to help! We are currently working on preparing comprehensive documentation covering submission, searching, and content retrieval via REST APIs. In the meantime, if you have any questions or need assistance, please don’t hesitate to open a ticket.
More information for the curious
Migrating content from one platform to another is a monumental undertaking. The information associated with each publication, such as the title, author, and abstract, needs to be meticulously transformed to fit a new data model while ensuring accuracy and integrity.
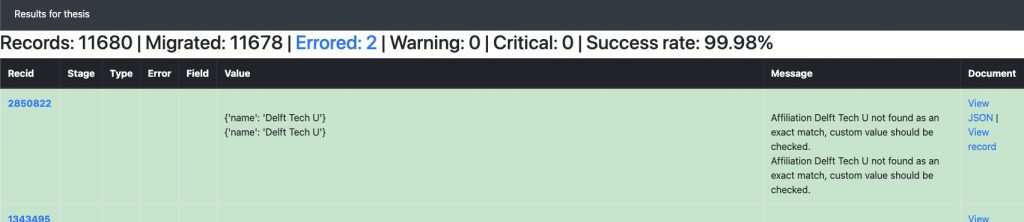
To manage this complex process, we developed a dedicated migration tool.
Migrator tool
This tool allows us to carefully review each transformation and correct any data discrepancies before the final migration. The CERN Scientific Information Service team has invested significant effort in curating all theses prior to their transfer.
Simultaneously, we developed essential features to support the thesis submission workflow. While these might not be immediately visible to the user, they are crucial for the repository’s proper functioning. For instance, the platform is equipped to:
Register Digital Object Identifiers (DOIs) when required, ensuring your work is easily citable and discoverable.
Utilize various CERN vocabularies and seamlessly integrate with GreyBook and other vital CERN databases.
Maintain a detailed record of user actions when modifying content through Audit Logs, ensuring transparency and accountability.
Synchronize content with the CERN Library Catalogue platform, allowing you to easily find information on how to borrow publications from the Library desk.
Harvest metadata from INSPIREHep, automatically archiving theses that have been published in this external repository, increasing their visibility within the high-energy physics community.
Our migration journey to the new platform is progressing smoothly, and we’re excited to announce the next key step: the migration of all theses from the former CDS. This transition is scheduled to take place in May 2025.
Read on to understand what this means for you.
Content migration: what to expect
All existing theses currently archived in the former CDS will be migrated to the new platform. You won’t lose any of this valuable research.
CERN Theses collection in the former CDS website
The migration will also include theses accessible in many other collections, such us:
ALEPH Theses
ALICE Theses
ATLAS Theses
BE Thesis
CDS Theses
CLIC Detector and Physics Study Theses
CMS Theses
DELPHI Theses
DIRAC Theses
DRD3 Theses
DRD7 Theses
FASER Theses
ISOLDE Theses
IT Theses
L3 Theses
LHCb Theses
LHCf Theses
n_TOF Theses
NA61 Theses
OPAL Theses
RD53 student, PHD thesis
RE29 Theses
RE41 Theses
RE42/CREEST Thesis
SHiP Theses
SND@LHC Theses
SY Thesis
TOTEM Theses
UA2 theses
UA4 theses
UA5 Theses
UA8 Theses
At the same time, all existing URLs pointing to theses in the former CDS will automatically redirect you to the corresponding content on the new platform. This ensures a smooth transition and avoids broken links.
The new CDS platform
The content will remain searchable and accessible in the former CDS. However, when you click on a thesis link within the former CDS, you will be seamlessly redirected to its new location on the new platform.
Finding content on the new platform
As we transition to the new CDS platform, we understand that easily locating content is extremely important. Please note that the final organization of content is still being refined and will continue to be enhanced in the coming months.
For this initial migration of theses, you will be able to find them in the following ways:
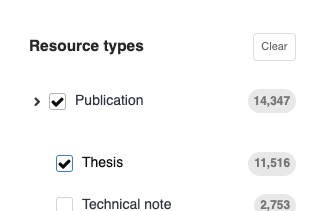
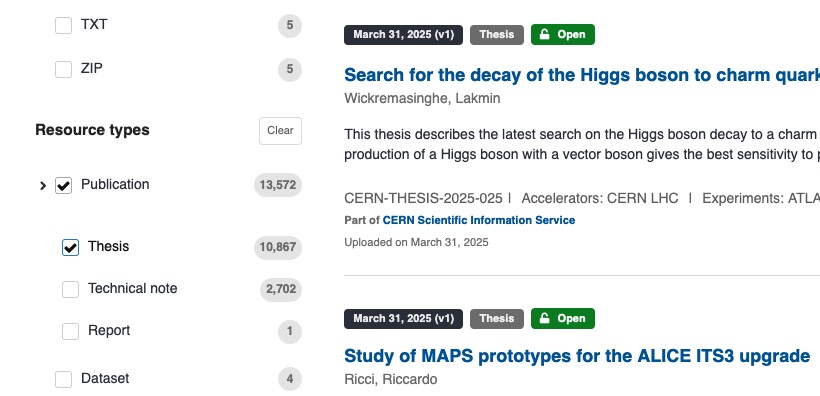
Keyword Searching: Utilize the main search bar with relevant keywords (author, title, subject, etc.) to find specific theses.
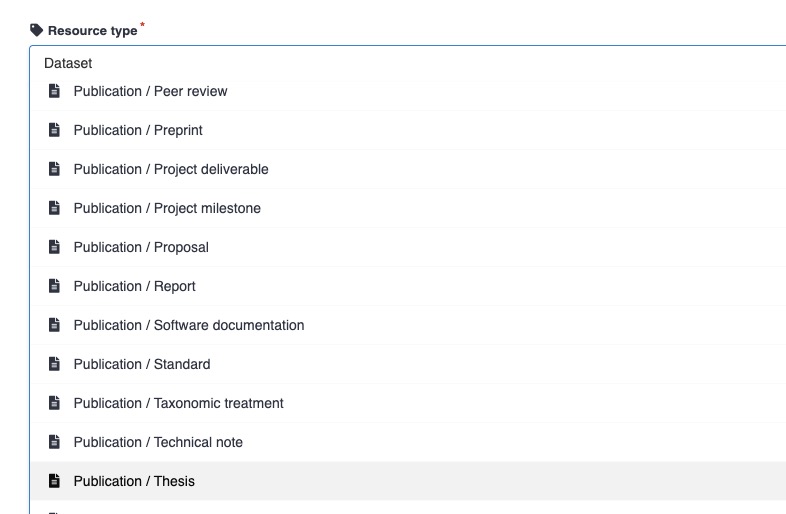
Thesis Filter: Once you perform a search, you will find a dedicated “Publication/Thesis” filter in the left-hand column of the search results page. Applying this filter will display only theses.
Search filters on the new CDS platform
Looking ahead: Collaboration Spaces
We are actively working on improving the content organization within the new platform. Later this year, our plans include the development of dedicated spaces for each collaboration. This enhancement will allow you to easily access all content associated with a specific collaboration in one centralized location. We will provide further updates on this exciting development as it progresses.
In the meantime, we are confident that the search and filtering functionalities will provide you with effective ways to locate the migrated theses.
New submissions: what’s changing
Once the migration is complete, all new thesis submissions will exclusively take place on the new platform. Any attempts to submit new theses through the former CDS submission interface will be automatically redirected to the correct submission process on the new platform.
We are preparing a dedicated documentation on how to submit thesis in the new platform.
Thesis resource type in the submission form in the new CDS
The current thesis submission workflow, including validation by the CERN Library before publication, will remain unchanged on the new platform.
Newly submitted theses will not appear in the former CDS platform. Implementing processes to synchronize new content between the two platforms would significantly complicate and delay the full migration of existing CDS content. Our priority is to ensure a timely and efficient transition of all existing research to the new, improved platform.
We’re here to help!
We understand that migrations can sometimes raise questions. If you have any concerns or require further clarification, please do not hesitate to contact us.
We are committed to making this transition as smooth as possible for everyone.
The last weeks of 2024 marked a big step for the CDS team and all CDS users: the first migration of CDS content to a new version of the platform—we have just completed the migration of the first collection—Summer Student Programme reports. We can now consider the CERN repository a production service.
This moment is historic not only for our service, but also for CERN.
A bit of history…
CDS was established over 20 years ago as the institutional repository of CERN, tasked with archiving, preserving, and disseminating the organization’s research output, administrative documents, and multimedia. It is powered by the Invenio framework version 1, which has also been adopted by numerous repositories worldwide.
While CDS has dutifully served the CERN community for many years, it has become evident that it requires a refresh in terms of user experience and available features to meet the demands of 2025 and future.
Drawing from the successful experience gained with Zenodo, we have developed InvenioRDM: a versatile digital repository designed for researchers. InvenioRDM has been created collaboratively with over 20 partners around the globe, and incorporates all the best FAIR (Findable, Accessible, Interoperable, and Reusable) practices, offering a modern user experience.
Over the forthcoming months, our focus will be on tailoring it to suit the requirements of an Institutional Repository while integrating features specific to CERN. In parallel, we will migrate the content of each collection, one by one, until the end.
How?
We have developed a migration plan spanning 2024 and 2025, with a subsequent phase planned for 2026. This long and complex migration, set to unfold over several years, will be guided by three core principles:
Engage: before initiating the migration of any collaboration using CDS, we will actively engage with its members. Our goal is to ensure a smooth transition that meets the needs of each community without disrupting their work. We will thoroughly analyze use cases and collaboratively establish timelines.
Simplify: we aim to make submitting content easier and more intuitive. By empowering users with tools to independently organize and curate their materials, we will enhance the overall user experience.
Standardize: we will adopt standardized content metadata practices to align with FAIR principles and Open Science best practices
Next steps
When will my content be migrated? Where should I upload new documents? Who should I contact? Don’t worry—these are questions we plan to answer together with you. We are committed to working closely with all content owners in CDS, gradually engaging with each group to share our plans and shape the future collaboratively.
Following the successful migration of the Summer Student reports, we’ve validated our migration processes and pipelines. Building on this success, we are now ready to tackle more complex challenges, with the next milestone being the migration of CERN Theses.
In parallel, we aim to explore the feasibility of bulk migrating content from small and medium experiments. Additionally, we plan to prototype a new review and comment workflow to address the needs of most users.
Keeping You in the Loop
This migration is an ongoing learning process, and we haven’t figured everything out yet! Your support and feedback are crucial to our success.
We’ve recently started documenting our migration journey and compiling information on a dedicated website, which is continuously evolving. Additionally, we’ll keep sharing updates and news right here.
If you have questions or concerns, don’t hesitate to reach out—we’re here to help.
Our new CDS repository is now more FAIR and more integrated with CERN services. Read below how.
DOI – do I need one?
A DOI (Digital Object Identifier) is like a permanent address for something on the internet, such as a research paper, article, or video. It’s a unique code that never changes, even if the location of the content moves to a new website.
Think of it like a tracking number for a package: no matter where the package goes, you can always find it using the number. Similarly, a DOI helps you find a document online, even if its web link breaks or changes.
When you click on it, it will always take you to the right place to access the content. This makes DOIs very useful for researchers, students, and anyone trying to find, share or cite information without worrying about broken links.
You do need, and you should prefer a DOI instead of other IDs, if:
the page of your document is public (the file might be restricted)
you want to keep permanent access to your article/paper/resource
you want any other researcher to be able to make references to your content (citations)
you want to share the content with the research community without worries about broken links
You do not need a DOI if:
your document is internal, fully restricted to to your collaboration
you do not need anyone to be able to cite your work/document
your document does not have research related nature
Choose your DOI option
Latest CDS upgrade, we introduced optional DOIs. When you are uploading a document, you can choose to:
Input an external DOI (for example, already provided by Zenodo.org, ArXiV.org or by a journal).
Obtain a new DOI, registered by CDS.
Avoid the creation of any DOI.
DOI selection optionsObtaining a DOI
When you choose to obtain a DOI from CDS, all the information associated with your record, except the file content, will be registered with DataCite.org. This includes metadata such as the title, authors, and other details, which may be accessed and harvested by third-party services.
Find my colleagues
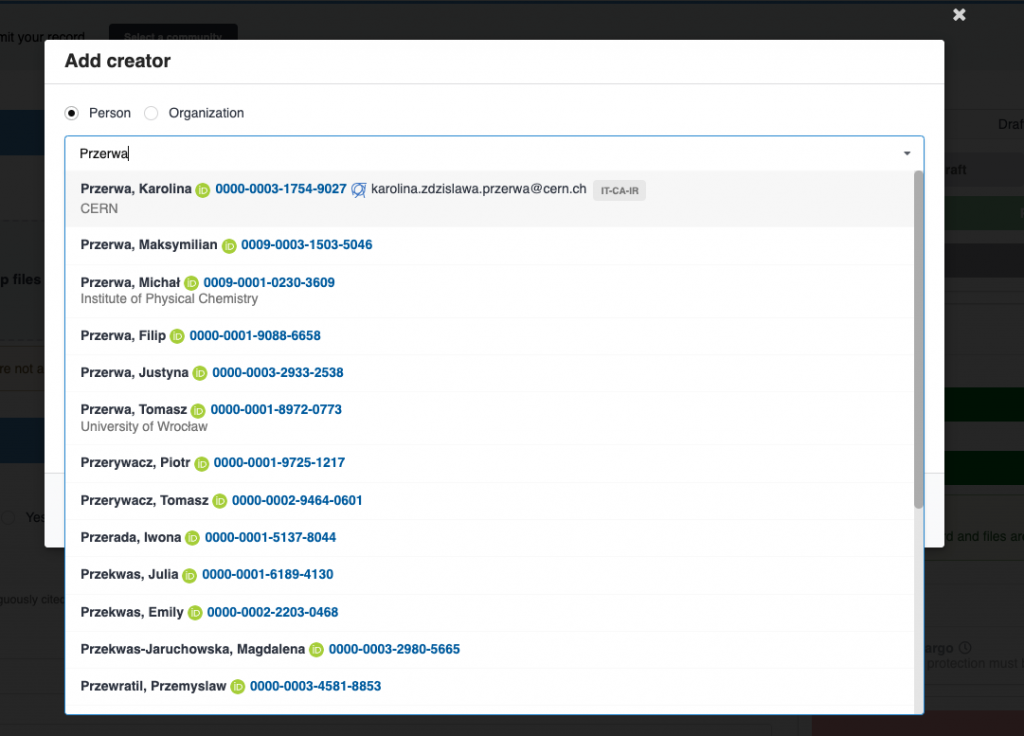
Since we are on the subject of submitting the content to https://repository.cern (aka CDS), how about providing the most accurate metadata possible, without hustle?
You can now easily find all of your CERN colleagues and external researchers with ORCiD profile when listing them as authors or contributors to your work.
But wait, what is ORCiD?
An ORCiD (Open Researcher and Contributor ID) is like a unique ID card for researchers (similar to DOI for research resources). It’s a special number that helps identify scientists, academics, and other contributors to research, so their work can always be linked back to them, no matter where it’s published.
Think of it like a social security number, but for researchers—it’s unique to each person and stays with them throughout their career. This is especially useful because many researchers might have similar names, or their names might appear differently in different publications.
For example: An ORCID might look like this: 0000-0001-2345-6789
With this number, all of a researcher’s work—papers, data, and other contributions—can be easily found and correctly attributed to them. It helps avoid confusion and makes it simple to track their achievements over time.
Creators and contributors
We have automated the import of the ORCID database, which, at the time of writing, contains over 21 million ORCID records, and the import of CERN users with an account.
Where can you add your colleagues to attribute for their contributions? There are dedicated fields in the deposit form:
Creators fieldContributors field
In the latest CDS platform upgrade, we improved the search capabilities and display of the autocompletion widget. You can now find your colleagues easier and add them even faster.
Preview of authors search
We highly recommend creating your own ORCID profile using this link. It is a must-have for any researcher!
Once you obtain and ORCID, you should connect it with your CERN Profile, using the Users Portal, as shown:
Finding affiliations
It is in a researcher’s best interest to provide the all possible metadata describing their research – more information they provide, higher the chance for other researchers to find about it.
Information about the researchers’ affiliations might be particularly important for highlighting the relationship with the organization which funded the research. Therefore, providing the up-to-date information about your affiliation will work well.
In CDS, we usually prefill that field for you, but our sources might not have the latest data, so you are able to fill the affiliations manually if needed. How? By using ROR identifiers (yes, yet another identifier!) or simply searching for the organization’s name.
A ROR identifier (Research Organization Registry identifier) is a unique, permanent ID used to identify research organizations worldwide. It ensures that institutions like universities, labs, and funding bodies are consistently and accurately recognized in research metadata, publications, and data repositories.
For example, many institutions have similar or changing names, which can create confusion. A ROR identifier solves this by providing a standardized, unchanging ID, like https://ror.org/01ggx4157 for CERN, which always points to the same organization.
ROR is open, free, and interoperable with other systems like DOIs (for publications) and ORCID (for researchers), helping improve the discoverability and tracking of research outputs. It’s a key tool for making research more connected and organized globally.
Affiliation field
Rich metadata
We made sure to put in place all these integrations with ORCiD, DOI, ROR and the CERN databases in order to make it easy for you to fill out the most metadata automatically (and quickly!). We strive for seamless user experience, and we really hope that all these features will make your upload easier and… more complete!
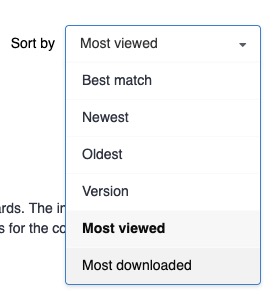
Find most viewed and downloaded
Curious to know what are the most viewed or most downloaded records? You can now easily find it out by sorting searching results.
🎄☃️❄️ Best wishes and a happy new year!
Image generated by ChatGPT with DALL·E.
The CDS team wishes you a joyful holiday season and a bright, successful start to the New Year!
We’re excited to announce a set of new features and improvements to the new CERN Document Server (CDS), now running on InvenioRDM v12! Our focus has been on making CDS more user-friendly and efficient for everyone.
The long list of all changes is detailed in the full changelog. Below, the main highlights more relevant to the CERN community.
What’s new?
Enhanced Search Accuracy
We’ve improved the search functionality to make finding records easier and more precise. Whether you’re looking for specific datasets or publications, the search engine is now optimized to deliver more accurate results, helping you locate the content you need faster.
Mathematical Formula Rendering
For researchers working with complex formulas, CDS now nicely renders LaTeX formulas within search results and records.
Content Policy and Terms of Use
To ensure transparency and safeguard users, we have added a Content Policy and Terms of Use to the platform. These documents clarify the rules regarding content submission and usage on CDS, helping maintain a safe and collaborative environment.
Introduction of sub-communities
One of the biggest updates is the feature of sub-communities. Communities on CDS can now be nested, meaning a community can have a parent community. This change brings more flexibility in organizing and structuring data, catering to the diverse needs of departments and research groups.
User Interface Tweaks
We’ve implemented a series of UI improvements, including fixing issues with community logos and adding enhanced loading icons during login and logout among other fixes. These small but impactful updates make the interface more user-friendly and visually coherent.
Migration of the 1st collection
Under the hood, we are working hard to migrate the very first collection of documents from the current CDS repository to our new platform. We are now in the process of testing the migration of documents and files, and ensuring the correct redirection of web links.
This is a very important milestone: it will prove that the migration processes that we have put in place are working as expected, and it will unblock the migration of the next collection of documents.
What’s next?
Our team is already working on new features for future releases:
Collections
We are developing a way to categorize records easily within a community (or independently) based on metadata. This allows users to organize and navigate records more intuitively.
Automatic Ingestion of ORCID and ROR Values
To save time and streamline workflows, we are working on automating the ingestion of ORCID and ROR data into the system, ensuring that author and organization identifiers are up-to-date without manual input.
Integration with CERN users database
We are working on making CERN users findable when searching for authors or collaborators during an upload.
Stay tuned for more updates, and as always, feel free to share your feedback with us!
We are happy to share some new updates about the CDS Videos platform. Our latest infrastructure upgrade introduces several improvements to enhance performance, security, and user experience. Here’s a summary of the key changes:
Upgraded search software
We’ve transitioned to OpenSearch, a central IT service that significantly boosts our search functionality and ensures a better integration with IT-provided services, removing maintenance’s redundancy.
Platform and security upgrades
We’ve upgraded our system from CERN CentOS 7 (CC7) to AlmaLinux 9 operating system. This change was part of the CERN campaign to upgrade all systems running on the former software as it is not actively supported anymore. This change ensures our platform’s resiliency and provides a more secure environment for all our users.
Improved upload features
Parallel uploads: We’ve addressed and resolved previous issues with multiple large parallel uploads. Uploading several large files simultaneously is now faster and more reliable.
Upload form improvements
We have made some changes in the upload form based on feedback we gathered from you. We hope they improve how you upload content on our platform.
Keywords: You can now enter keywords separating them with commas. That will allow you to paste e.g. “keyword1, keyword2” and the system will automatically convert them into 2 separate tags for you after pressing ENTER, improving the process of tagging and categorizing videos.
Date: We’ve enhanced the date input functionality to allow you to input dates directly instead of using always the date picker widget. That is useful when you want to input a rather old date.
Contributors:
When you enter a custom contributor name, the system will convert the name automatically to a capitalized version e.g. “doe, joe” will be converted to “Doe, Joe“, ensuring a consistent appearance across the platform.
We’ve added a new contributor role, “Subtitles by” so you can give proper credit to those who provide subtitles for your videos.
These upgrades are part of our continuous efforts to improve the CDS Videos platform. We hope these changes will provide you a better, more efficient experience.