We are happy to announce several new features now available on CDS.
GitHub and GitLab software archiving
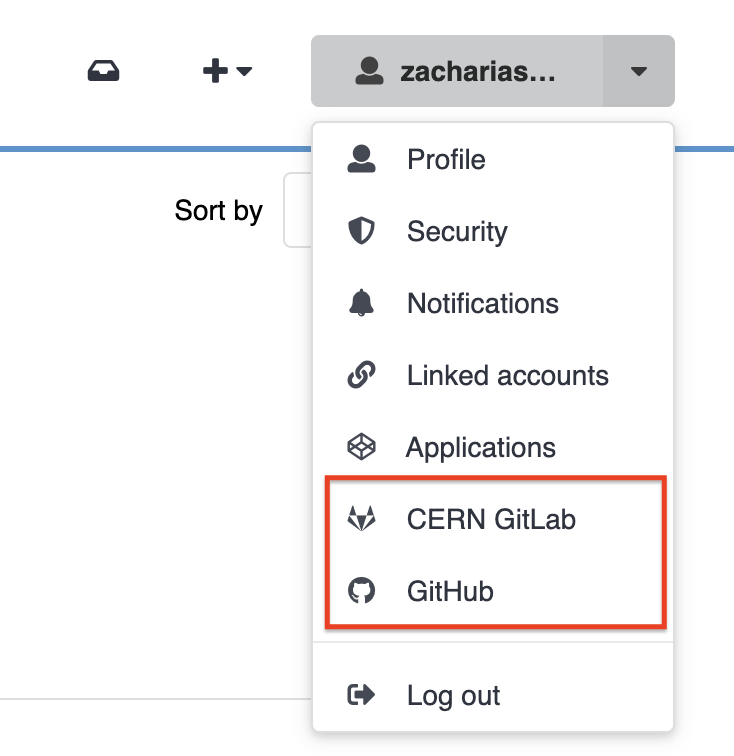
You can now connect your GitHub or CERN GitLab account to CDS and archive your software releases automatically. Once you enable a repository, each new release will create a record on CDS with a ZIP archive of the repository contents and automatically extracted metadata.
To get started, open the user menu and select CERN GitLab or GitHub, then enable the repositories you want to archive.
You can also assign each repository to a community and track the status of each release directly from CDS.
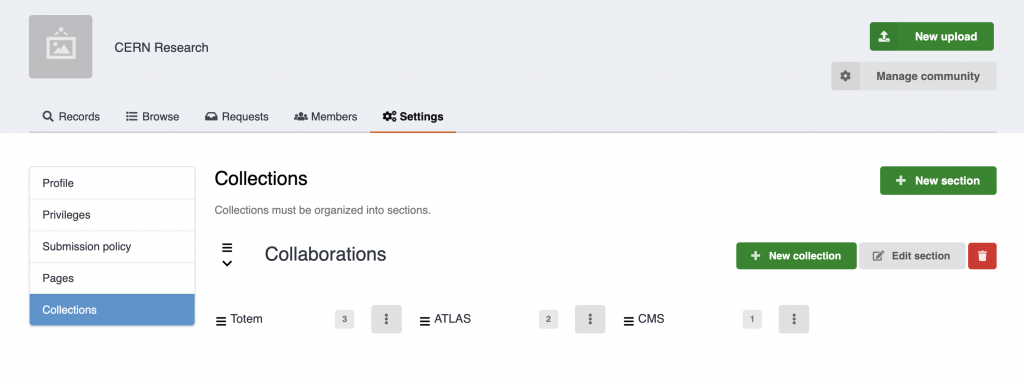
Community managers can now organize their community’s records into collections — curated groupings based on search filters that make it easier for users to browse and discover content by topic or theme.
Collections are managed from the community settings page, where owners can create sections, add nested collections, define the search query behind each collection, and reorder them via drag and drop.
We have simplified the query syntax for common search fields. You can now use shorter, more readable terms when searching. For example:
Before
After
metadata.title:<value>
title:<value>
metadata.identifiers.identifier:<value>
identifier:<value>
The full list of supported fields and advanced query options — including phrase search, date ranges, wildcards, and more — is now covered in the documentation.
All of the above features are now covered in the CDS documentation 🚀. If you run into issues or have ideas for improvements, let us know through the usual CDS support channels.
If you’ve ever reviewed a submission in CDS and ended up juggling email threads, chat messages, and half-remembered notes — this update is for you.
We’ve just rolled out improved commenting features in repository.cern (new CDS platform). That means discussions about submissions will be easier to navigate and use!
We also added 3D images previewer and few copy buttons to facilitate record links distribution – to share with your colleagues or your users.
You can read the full comments feature documentation here:
Disclaimer: the full documentation is still under construction 🏗️ and will be gradually updated
But below is the short version of what’s new — and why it should make your life easier.
What’s new?
Improved submission review comments
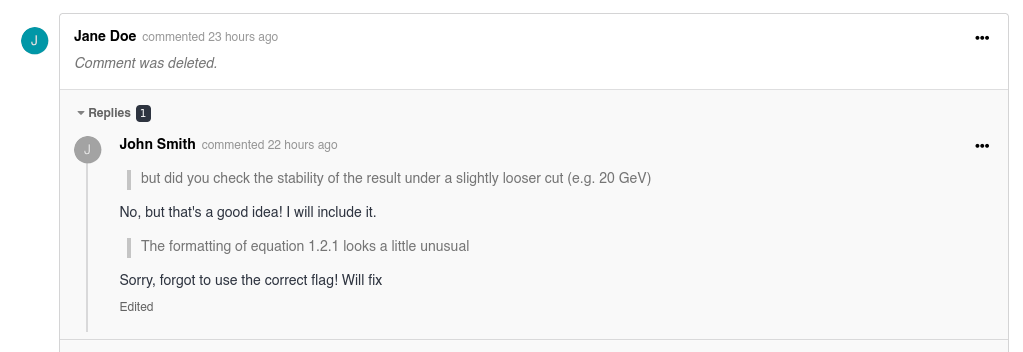
When a record is submitted for review, reviewers and submitters can now:
Reply to specific comments in threaded discussions
Quote another comment when responding
Share a direct link to a comment
Use simple formatting and LaTeX for equations
Temporarily keep draft comments auto-saved in the browser
Lock discussions when a review is finished
What does it mean in practice? No more copy-pasting comments back and forth. No more losing long responses because a browser tab was accidentally closed.
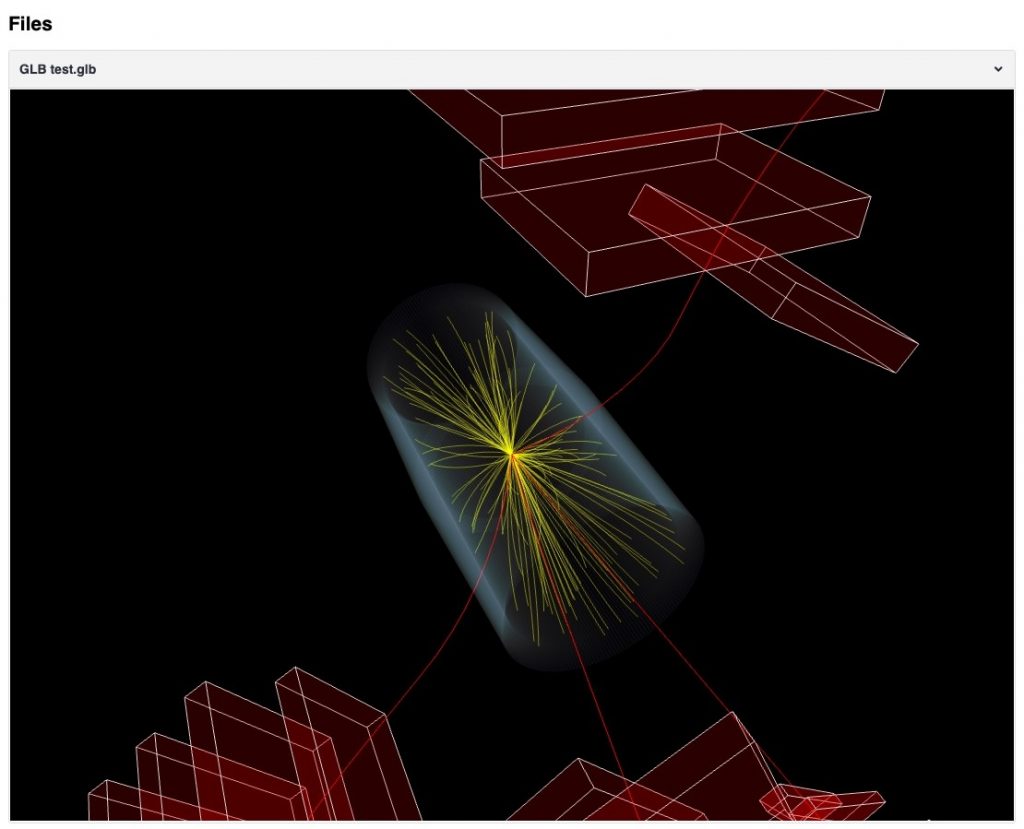
File previewer
From now on GLB files can be viewed directly on the record page:
3D event previewer
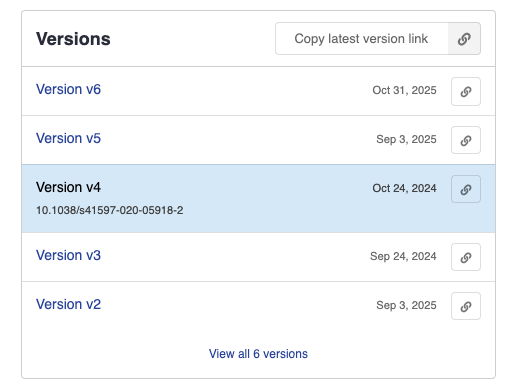
Version aware sharing
Would you like to share a link pointing always to the latest version of the record, but you don’t need a DOI? Or instead, do you really need a link to one of the previous versions? Use these new link 🔗 buttons:
Why we built this
CDS reviews are often collaborative: collaboration librarians, editors, conveners, authors — everyone has a say. Until now, most of that discussion happened outside the repository. That made it hard to track decisions and context over time.
With in-place commenting:
Feedback stays attached to the submission
Everyone sees the same discussion
It’s easier to follow what has been addressed and what hasn’t
Future curators can understand why a decision was made
Curators can lock the discussion once the review is complete, so the conversation stays as a record of the process.
This is a part of the process
We see this as the first step toward smoother community workflows in the CDS platform. As always, we’ll keep improving based on how people actually use the system.
If you run into issues or have ideas for improvements, let us know through the usual CDS support channels.
Thanks to everyone who tested early versions and provided feedback — it helped shape this release.
The last weeks of 2024 marked a big step for the CDS team and all CDS users: the first migration of CDS content to a new version of the platform—we have just completed the migration of the first collection—Summer Student Programme reports. We can now consider the CERN repository a production service.
This moment is historic not only for our service, but also for CERN.
A bit of history…
CDS was established over 20 years ago as the institutional repository of CERN, tasked with archiving, preserving, and disseminating the organization’s research output, administrative documents, and multimedia. It is powered by the Invenio framework version 1, which has also been adopted by numerous repositories worldwide.
While CDS has dutifully served the CERN community for many years, it has become evident that it requires a refresh in terms of user experience and available features to meet the demands of 2025 and future.
Drawing from the successful experience gained with Zenodo, we have developed InvenioRDM: a versatile digital repository designed for researchers. InvenioRDM has been created collaboratively with over 20 partners around the globe, and incorporates all the best FAIR (Findable, Accessible, Interoperable, and Reusable) practices, offering a modern user experience.
Over the forthcoming months, our focus will be on tailoring it to suit the requirements of an Institutional Repository while integrating features specific to CERN. In parallel, we will migrate the content of each collection, one by one, until the end.
How?
We have developed a migration plan spanning 2024 and 2025, with a subsequent phase planned for 2026. This long and complex migration, set to unfold over several years, will be guided by three core principles:
Engage: before initiating the migration of any collaboration using CDS, we will actively engage with its members. Our goal is to ensure a smooth transition that meets the needs of each community without disrupting their work. We will thoroughly analyze use cases and collaboratively establish timelines.
Simplify: we aim to make submitting content easier and more intuitive. By empowering users with tools to independently organize and curate their materials, we will enhance the overall user experience.
Standardize: we will adopt standardized content metadata practices to align with FAIR principles and Open Science best practices
Next steps
When will my content be migrated? Where should I upload new documents? Who should I contact? Don’t worry—these are questions we plan to answer together with you. We are committed to working closely with all content owners in CDS, gradually engaging with each group to share our plans and shape the future collaboratively.
Following the successful migration of the Summer Student reports, we’ve validated our migration processes and pipelines. Building on this success, we are now ready to tackle more complex challenges, with the next milestone being the migration of CERN Theses.
In parallel, we aim to explore the feasibility of bulk migrating content from small and medium experiments. Additionally, we plan to prototype a new review and comment workflow to address the needs of most users.
Keeping You in the Loop
This migration is an ongoing learning process, and we haven’t figured everything out yet! Your support and feedback are crucial to our success.
We’ve recently started documenting our migration journey and compiling information on a dedicated website, which is continuously evolving. Additionally, we’ll keep sharing updates and news right here.
If you have questions or concerns, don’t hesitate to reach out—we’re here to help.
We’re excited to announce a set of new features and improvements to the new CERN Document Server (CDS), now running on InvenioRDM v12! Our focus has been on making CDS more user-friendly and efficient for everyone.
The long list of all changes is detailed in the full changelog. Below, the main highlights more relevant to the CERN community.
What’s new?
Enhanced Search Accuracy
We’ve improved the search functionality to make finding records easier and more precise. Whether you’re looking for specific datasets or publications, the search engine is now optimized to deliver more accurate results, helping you locate the content you need faster.
Mathematical Formula Rendering
For researchers working with complex formulas, CDS now nicely renders LaTeX formulas within search results and records.
Content Policy and Terms of Use
To ensure transparency and safeguard users, we have added a Content Policy and Terms of Use to the platform. These documents clarify the rules regarding content submission and usage on CDS, helping maintain a safe and collaborative environment.
Introduction of sub-communities
One of the biggest updates is the feature of sub-communities. Communities on CDS can now be nested, meaning a community can have a parent community. This change brings more flexibility in organizing and structuring data, catering to the diverse needs of departments and research groups.
User Interface Tweaks
We’ve implemented a series of UI improvements, including fixing issues with community logos and adding enhanced loading icons during login and logout among other fixes. These small but impactful updates make the interface more user-friendly and visually coherent.
Migration of the 1st collection
Under the hood, we are working hard to migrate the very first collection of documents from the current CDS repository to our new platform. We are now in the process of testing the migration of documents and files, and ensuring the correct redirection of web links.
This is a very important milestone: it will prove that the migration processes that we have put in place are working as expected, and it will unblock the migration of the next collection of documents.
What’s next?
Our team is already working on new features for future releases:
Collections
We are developing a way to categorize records easily within a community (or independently) based on metadata. This allows users to organize and navigate records more intuitively.
Automatic Ingestion of ORCID and ROR Values
To save time and streamline workflows, we are working on automating the ingestion of ORCID and ROR data into the system, ensuring that author and organization identifiers are up-to-date without manual input.
Integration with CERN users database
We are working on making CERN users findable when searching for authors or collaborators during an upload.
Stay tuned for more updates, and as always, feel free to share your feedback with us!
With the LTS release (v9) and the latest release (v10), InvenioRDM has reached the maturity needed for production-ready digital repository websites. InvenioRDM is a generic data management repository, developed by our team in collaboration with many partners all over the world. Free to use and open-source.
As first milestone, we have created and deployed the new instance of CDS and also migrated a selected set of records, metadata-only. This initial setup will allow us to iterate with the process of data migration, expanding incrementally the number of records and improving the data quality.
In the first quarter of this year, we will continue working on the InvenioRDM product, adding more features and integrating them in the new CDS website.
We will also start an analysis of the feature-set available in the current CDS, but still missing in the new platform: thanks to this, we will be able to come up with a plan for the next steps.
We are very excited to finally see the new CDS taking shape! Stay tuned for future announcements!